
Big Data Management. 1 - Introduccion al Big Data para trading
En este articulo se explica las caracteristicas y cualidades de un datalake, al mismo tiempo que se explica un plan de ejecucion para su creacion basado en python y arcticdb.

Uno de los principales retos a solucionar, dentro del research cuantitativo, es la gestión de los datos. Históricamente, los datos han sido recursos inaccesibles, caros y únicamente disponibles para grandes instituciones. Con el paso del tiempo, todas estas barreras han sido superadas, democratizando su acceso a todo usuario, eliminando su principal barrera de entrada (los altos costes) y dejando los precios en unos anecdóticos dólares.
En mi experiencia profesional, he podido trabajar con diferentes arquitecturas dedicadas a storear, capturar, ordenar, y procesar datos. Y siempre he llegado al límite de la arquitectura, con problemas para seguir avanzado.
Dichas arquitecturas parecen diseñadas para cumplir unas funcionalidades concretas, y no para ser resiliente en el futuro. Siendo soluciones que sirven para «salir del paso», pero no para crear bases de datos con una perspectiva de largo plazo.
En pleno 2023, tras el brutal salto tecnológico que ha experimentado la sociedad, las tecnologías basadas en Big Data, son asequibles, fácilmente implementadles, robustas y seguras. Y la utilización de bases de datos clásicas (SQL) sobre datos financieros han sido desfasadas, por soluciones más actuales que además aportan las grandes ventajas que nos proporcionan las bases NoSQL.
Vocabulario
Primero, explicamos los conceptos básicos necesarios para entender el valor del uso de una tecnología sobre otra.
Datalake
Un datalake es un objeto de espacio, que puede estar en local, pero que usualmente se despliega en la nube, que sigue una estructura de volcado de la información en un único punto NoSQL. Mediante la centralización facilita las labores de mantenimiento y administración.
Un ejemplo visual podría ser esta imagen. Donde todas las fuentes de input de data, se vuelcan en un datalake, al mismo tiempo los clientes hacen consultas al datalake sobre la información que necesitan.

Data Management
El Data Management es la disciplina que gestiona todo lo relacionado sobre la gestión de datos. Dentro del mundo del research de trading cuantitativo, debemos crear las soluciones que mejor se adapten a un entorno de research profesional. Cuando hagamos referencia al Data Management, nos referimos desde la selección de proveedor de servicio hasta la integración con el modelo de desarrollo con los datos gestionados.
Big Data
Cualquier arquitectura de datos que cumpla con las siguientes características:
- Velocidad:Que sea posible crear, acceder, almacenar y procesar la información de forma ágil.
- Variedad: Que se pueda almacenar todo tipo de información. Que los esquemas sean flexibles, y no existan restricciones a la información que se almacena.
- Volumen: Estar diseñado para poder trabajar cantidades ingentes de datos. Estar listas para procesar muchísima información de forma muy rápida y de todos los tipos.
Object Store (S3)
Siendo extremadamente simplistas, podríamos definirlo como un disco duro gigante en la nube, el cual podemos utilizar como almacenamiento en cualquier momento, únicamente autentificándose con un usuario y una contraseña.
Los discos están en los data centers repartidos por el mundo de Amazon, únicamente elegimos una localización, y una tecnología de velocidad de lectura y escritura (a más rápido, más caro, obviamente) y olvidarnos del resto.
Esto proporciona la arquitectura perfecta para el desarrollo de aplicaciones nativas en la nube, dado que las operaciones se ejecutan en el "client-side" mientras que el storage está en un punto seguro de Amazon. Obteniendo lo mejor de cada mundo.
Amazon AWS EC2
Amazon Web Services EC2 es un servicio de "System as Service". Seleccionamos una capacidad de potencia, un disco duro y un sistema operativo, y ejecutamos una máquina virtual en los data centers de Amazon, en cuestión de segundos. Su tarificación es por minutos, y se pueden alojar desde pequeños proyectos personales sin ningún valor, hasta las infraestructuras más complejas, como las empresas tecnológicas más valiosas. Además dispone de un asistente para usuarios novatos, denominado Amazon Lightsail, el cual facilita todo el proceso, a nivel chimpancé (nivel donde cualquier persona, podría lanzar el servicio)
Recomiendo la investigación en los servicios de Amazon Web Services, dado que es uno de nuestros sponsors, y utilizaremos sus servicios siempre que sea posible. Además de ofrecer otras alternativas por si alguien desea investigar otros proveedores.
Diferencias entre SQL y NoSQL
Las bases de datos SQL son relacionales, y las NoSQL utilizan diferentes métodos de enlace como los grafos o el clave valor. Lo cual permite una mayor flexibilidad al no depender de un esquema rígido como las bases de datos SQL tradicionales. Además de la facilidad de su escalado, provocando un porcentaje bajo de inconsistencia temporal.
SQL es apropiado para proyectos que priorizan la consistencia y la integridad, mientras que las bases NoSQL priorizan la escalabilidad y los valores del big data. Pudiendo ser inconsistentes en ciertos puntos, hasta que acabe el proceso total. (Problema que mediante ArcticDB vamos a solucionar de forma satisfactoria)
Datos

Un proceso de research, mediante capacidad de procesado de información, debe formular una hipótesis válida, que describa nuevas ventajas competitivas para la extracción de valor del mercado (alpha). Para poder explorar todo el espectro de mercado, solo hay una única fuerte de certidumbre. Los datos.
Los datos son hechos. Son información compartida por participantes en el activo sobre hechos relevantes que ocurren. La simplificación más básica que se realiza en finanzas es el evaluar, dentro de un espacio temporal, el open, high, low y close, y volume. Pero la cantidad de información que genera un activo durante su ciclo de vida, es muchísimo más extensa, que la simple información del precio.
Dentro del Big Data, podemos clasificar todos los datos, en tres grandes grupos:
- Datos: La información pese. El dato capturado
- No Datos: Los datos cuando no hay datos.
- Metadatos: Los datos que generan sobre los datos.
Para poder entender mejor este concepto. Vamos a poner un ejemplo. Estamos capturando los datos que emite nuestro propio teléfono móvil. Nuestro requisito es la cantidad de datos por segundo que envía, sin importar nada más, nuestro único criterio cuantitativo, es la cantidad de información enviada.
Los datos se caracterizan por ser información interpretable por todos sus usuarios. No lleva a cabo a ambigüedades. En nuestro ejemplo sería, cantidad de datos por hora que enviamos.
Los no-datos, son los datos proporcionados cuando no hay datos. Muchos podéis preguntaros ahora mismo. ¿Pero si no hay datos, que más me dan los datos?
Pues son fundamentales. Por ejemplo, siguiendo nuestro ejemplo, los no datos serían exactamente, que los datos enviados por hora son igual a 0. Al no tener información, guardaríamos como no datos, los periodos temporales donde no han existido datos, y otros datos como los metadatos activos en dicho momento.
Y ahora entramos con los metadatos. Son información que contextualizan al dato, información que al ser eliminada, no altera el dato, pero que al ser añadida, proporciona información vital.
Siguiendo con el ejemplo, los metadatos podría ser, la ubicación del teléfono, último nivel de señal recibido, o cualquier otra variable que se esté generando en dicho momento.
Muchísimas empresas han gastado ingentes cantidades de dinero, para poder recolectar y almacenar la mayor cantidad de metadatos posibles, sin tener muy claro el uso que les darían, y ahora están empezando a incluirlos dentro de los modelos de machine learning.
Aunque ello es tan solo el principio, ya forman una parte muy necesaria de cualquier investigación sobre datos.
Entonces, con toda esta información podríamos inducir muchísima más información. Es decir, combinando los datos, es decir, la cantidad de paquetes que enviamos por hora, con los no-datos, que son los datos, de cuando no hay datos, y la metadata.
Generamos conocimiento adicional desconocido, que nos aporta pistas de donde está la solución, pero no se puede concluir de forma irrefutable, sino adquiere cierta significancia estadística a posterior ( y no me refiero a 30 casos).
Por ejemplo, podríamos deducir que:
- En las horas de mayor actividad -> Está libre
- En las horas de menor actividad -> Está trabajando
- En las horas donde está de noche -> Es su hogar
- En las horas donde está de día -> Es su trabajo
- En las horas donde está los fines de semana -> Es su hogar
- Etc...
Al final, mediante la combinación de las tres fuentes básicas de información, inferimos nuevos datos, concluimos en nueva información, que en muchos casos será real, y en otros no, porque por ejemplo, cualquier persona que trabaje solo fines de semana y en casa, el modelo no lo catalogara correctamente).
Pero los modelos no son oráculos dispuestos a dar una solución personalizada para cada caso, son modelos que intentan adaptarse a una tendencia general de la sociedad (y por consecuencia, la importancia del nowcasting, para entender en que momento exacto el modelo ha dejado de tener validez estadística)
En finanzas ocurre lo mismo, por ejemplo en una cartera de n activos, las variables que pueden condicionar el retorno de mañana de dicho portfolio podrían ser casi infinitas, pero se han establecido ciertos mecanismos mediante la observación y la inducción de información, por la cual usando la combinación de diferentes fuentes de información, podemos generar nueva información mediante la inducción, no conocida con anterioridad.
Estamos hablando de algo tan simple como el impacto de un evento en el precio de una compañía, o como cuando la tónica general de un sector es adquirir momentum, todas las empresas del sector, sin importar su estado interno, tienen un mejor desempeño que cuando no existe dicho momentum.
Y de ahi, la importancia de los datos. Dentro del mundo cuantitativo, dentro del proceso de descubrimiento de Alpha, los datos lo son todo.
Y con unos datos de baja calidad, lo mas probable sera obtener un research de baja calidad.
La materia prima, en el research cuantitativo, son básicamente dos.
- Capacidad de procesado de información: Alberga toda la infraestructura necesaria para llevar a cabo los procesos cuantitativos que determinen las soluciones a nuestras preguntas. Estamos hablando de recursos fisicos. CPU, RAM , HD, GPU, TPU...
- Los datos en si. La información es poder. Además de ser la fuente principal de entradas de información. Y cuando hablamos de datos, no hablamos únicamente del precio. Hablamos de metadata del activo, datos fundamentales, noticias, etc. además de una nueva clase de datos que se está estandarizando últimamente como son los llamados datos alternativos o alternativa data. Son datos totalmente exógenos, pero con componentes muy determinísticos y gran repercusión en el objeto del estudio. Como puedan ser un análisis de una red social, un análisis de las capacidades de los proveedores o clientes o cualquier otra información relevante.
Requisitos

Hay infinitas soluciones para almacenar series temporales. Pero dado que esta solución, debería perdurar en el tiempo, con capacidad de adaptarse a todos los cambios imprevistos que pueda albergar el futuro, nuestro datalake debe cumplir ciertos requisitos para garantizar que esta tecnología será óptima, tanto a día de hoy, como a futuro.
Los requisitos iniciales son los siguientes:
- pd.DataFrames() : El uso de pandas dataframe tanto en la entrada como en la salida, es algo esencial.
- Sin necesidad de servidores: Que pueda ser directamente volcada sobre una estructura de objetos en la nube, manteniendo unos requisitos muy estrictos de velocidad, seguridad y estabilidad
- Que sea no estructurada, Asumiendo que el futuro es incierto, y en cualquier momento puede aumentar la cantidad de información disponible para su recolección sobre un mismo activo. las estructuras fijas clásicas estás totalmente obsoletas para este propósito.
- Snap y versiones. Que puedan tener acceso a diferentes versiones de un mismo símbolo, o de toda la base de datos mediante Snap
- Metadata. La gestión de los metadatos es primordial. Es necesaria que tenga la capacidad de añadir metadata sobre cualquier símbolo o base de datos.
- Respaldada. Que sea una tecnología que tenga financiación institucional, o directamente algun hedge fund o institución de relevancia involucrada en su desarrollo.
Tras hacer muchas pruebas de arquitecturas, acabe encontrando la mejor solución para mi. Incluso he llegado a crear unos transcodeadores de pd.DataFrame a datos binarios directos. Pero el remedio, fue peor que la enfermedad...
ArcticDB
La primera vez que tuve contacto con ArcticDB fue en una PyQuant de 2017, donde unos tipos desconocidos en aquel momento, tenían montado una arquitectura MongoDB para almacenar datos. En su momento, fue una gran revolución dado su mecanismo de pd.DataFrame in, pd.DataFrame out. Facilitando muchísimo todo tipo de labores, además de la integración universal en todos los campos del research, dado que pandas y numpy monopolizan el espectro de data-science mundial.

Pero al ser un proyecto tan nuevo, y con tantas partes criticas dentro de la arquitectura, lo investigue a fondo, y lo abandone, con la esperanza de volver más tarde, y ver un proyecto maduro y usable.
Al utilizar un servidor intermedio, como mongoDB, era mas propenso a errores catastróficos(en comparación con la solución utilizada), que en esos momentos no estaba dispuesto a asumir.
Arcticdb viene de manos de MAN Group, una entidad con una larga trayectoria en la aplicación de modelos cuantitativos a mercados financieros.
Por lo que sabía, qué salvo salto tecnológico hacia una tecnología superior, la idea que tenían los chicos de Arcticdb era una genialidad, y no les costaría demasiado encontrar financiación.
Y así ha sido, unos cuantos años más tarde y tras firmar algún acuerdo con bloomberg han creado un motor en c++, el cual tiene una total integracion mediante una librerías de Python.
Llevando cualquier proyecto basado en pd.Dataframe hacia una auténtica arquitectura escala de big data (Petabyte-Scale). Proporcionó capacidades de proceso sobre grupos de datos, extremadamente grandes, con gran solvencia`.
¿Y que han conseguido con esto?

Pues básicamente crear un sistema de datalakes, capaz de procesar billones de filas en segundos o lo que se denomina Petabyte Scale, de una forma que se integra en el pipeline de todo researcher de Python, mediante su formato pd.DataFrames in y pd.DataFrames out, sin necesidad de servidor, dado que va volcado directamente en un objeto tipo S3, y totalmente listo para implementar en producción en un entorno real.
- Nos permite procesar billones de filas y columnas por segundo
- Nos permite escalar desde un Notebook, hasta un Cluster de producción con total estabilidad y sin perdidas de rendimiento
- Proporciona una datalake a los researchers, en cualquier lugar dado que es un producto cloud-native, facilitando los procesos de creación de datasets y universos. En cualquier lugar, en cualquier entorno y bajo cualquier circunstancia.
- Aportando NoSQL a los pd.DataFrames clasicos y las ventajas que todo ello conlleva la hora de realizar mantenimientos
- Sin esquemas fijos, y pudiendo cambiar la estructura de la base de datos en cualquier momento, sin consecuencias
- Modificaciones seguras de los datos, gracias a los versiones a nivel de símbolo, o los snaps a nivel de datalake. Donde cada ticker nunca es eliminado, sino creada una nueva versión. (Aumentando el tamaño de la base de datos, pero proporcionó una salida ante cualquier error, y reduciendo puntos críticos).
Todas estas características facilitan el acceso a tecnologías con una capacidad de cálculo, que tan solo unos 10 años tras, serian inimaginables de que un inversor retail pudiera desplegarlas sin un soporte institucional.
Dado a su altísimo rendimiento, es una base de datos apta para utilizar con métodos de modelación y ejecución de alta frecuencia.
Arcticdb esta totalmente preparado para el streaming de ticks, desde L1 y L2 y orderbook tickdata, pudiendo procesar billones de filas y cientos de columnas en segundos
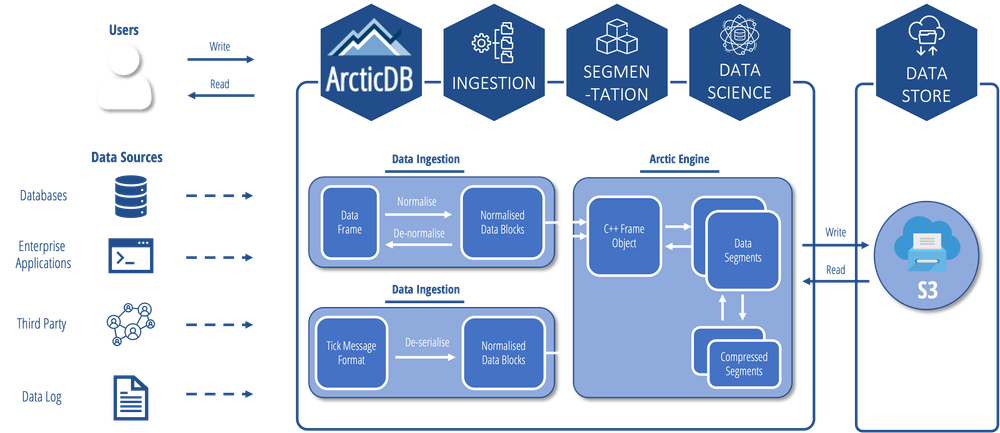
Una vez presentada la tecnología principal del Datalake. Vamos a establecer una arquitectura mínima necesaria para poder implantar el proyecto.
El objetivo de este despliegue no es crear el datalake más rápido del mercado. Únicamente generar un datalake económico (a nivel infraestructura), facil de mantener, y con una calidad, velocidad y estabilidad más que suficientes para las labores de research en el dia a dia, y aun así más veloces que las arquitecturas convencionales utilizadas actualmente.
Arquitectura Utilizada
Uno de nuestros principales requisitos, es que el datalake sea server-less. Es decir, que no necesite ningún sistema operativo para lanzarlo. Que esté diseñado para ser ejecutado de una manera nativa en la nube.
Facilitando el acceso a los usuarios designados mediante un API KEY al datalake personalizado. El secreto para no necesitar ningún tipo de metal para realizar las operaciones, es que estas operaciones se procesan en el cliente, es decir, el kernel de python que esté ejecutando esa instrucción está enviando la consulta exacta al S3, para que devuelva los recursos solicitados.
Al utilizar este tipo de tecnológicas conseguimos:
- Mayor escalabilidad, dado que el almacenamiento es infinito en caso necesario, y se aumenta en función de las necesidades del momento.
- Mayor estabilidad: Al eliminar el sistema como tal de la ecuación, minimizamos las contingencias por un error en un update del sistema operativo o cualquier otro tipo externo a la base de datos.
- Mayor Rapidez: Al poder utilizar almacenamiento de alta velocidad en amazon S3, únicamente necesitamos garantizar una conexión de linea lo suficiente rápida como para poder llevar a cabo las tareas de data ingest. Actualmente, estoy consiguiendo unas velocidades de 6 gbps en subida y 6.5 gbps en bajada utilizando Amazon S3 Storage en el datacenter de Zaragoza (Recuerda elegir siempre la ubicación más cercana a tu país)
Yo utilizo Amazon S3. Pero existen alternativas, nivel hobby, que pueden suplir perfectamente las necesidades, y todo ello por menos de 0.002€/gb/mes
Requisitos de los datos

En esta revolución tecnológica que se está viviendo en los mercados financieros, los datos, los no datos y los metadatos, están tomando el poder.
Toda fuente de alpha descubierta en la historia de las finanzas, procede de un descubrimiento en la información disponible, y su posterior explotación
Como dijimos anteriormente, los datos son la fuente principal de todo. Y como si de una receta culinaria se tratase, a mayor calidad de la información, mejores resultados de los modelos.
Los datos necesarios son muy diversos en función del activo, por consecuencia, necesitamos poder asignar esquemas en la información, pero que estos no sean fijos. Que las estructuras de la las bases de datos, mediante versiones, puedan mutar a nuevos esquemas (al mismo tiempo que puedan retroceder, en caso de contingencias).
Los datos que vamos a necesitar se estructuran de la siguiente forma:
- Precio: Datos en formato OHCLV. La información básica dado que muchas funciones críticas que los modelos dependen de ellos, tales como el cálculo de modelos en función de la variación en su valor, como los puntos de ejecución. La granularidad de los datos depende de tus necesidades, pero al estar diseñada para resistir todo tipo de cargas y procesos de alta frecuencia, soporta cualquier tipo de datos que necesites almacenar.
- Metadata: Los metadatos son parte fundamental dentro de mi pipeline, dado que la utilizo para crear universos de activos. En ella almacenaré toda la información que considere relevante, y que no cambia a lo largo del tiempo, como pueda ser, la divisa de un activo, o una etiqueta obtenida por algún modelo de clasificación... Cualquier otra información invariable sera considerada como metadata.
- Fundamental: Los datos fundamentales son básicos para poder tener un datalake en condiciones necesarias. Dado que aporta diferentes criterios de clasificación de empresas, independientes al precio. Además, existen diferentes tipos de información, además de sus estados financieros, sus tops moldes institucionales, o sus retiros de valoración en función a algún framework de moda, actualmente el ESG, entre muchos otros. Además, debemos tener en cuenta, que existirán datos únicos, y existiran datos con histórico, por consecuencia el tener un esquema dinámico, facilita a futuro cualquier contratiempo, que puede surgir en este aspecto.
- Alternativa: Además de todos los tipos de datos explicados, también tenemos datos alternativos para añadir al datalake, cuando hablamos de datos alternativos hacemos referencia a datos como el análisis de sentimiento de una red social, o de las noticias publicadas en medios relevantes, como cualquier otra información no estandarizada por la industria, que consideres que pueda ser relevante para cualquier modelo.
- LOB Level: En muchos casos, vamos a necesitar trabajar con Order books. Existen dos formas de servirlos por parte de los databrokers, una es un agregado por tiempo, y el otro es un flujo constante de cambios en el libro. Estas estructuras son muy costosas a nivel de información por intervalo de tiempo, pero muy utilizadas. Especialmente necesarias para trabajar con futuros y spreads, incluso también muy recomendable para trabajar con opciones, dado los spreads habituales para cruzar las órdenes.
- Macro: Otra información necesaria dentro de nuestro datalake, será la información macroeconómica de los países, tanto los históricos de la deuda nacional, como de diferentes ratios macroeconómicos básicos. Toda esta información puede ser incluida a posterior en modelos y estudios, aportardo mayor gama a la investigación.
- Opciones para los datos
Existen múltiples alternativas para elegir data brokers o data providers. Antiguamente, existía un claro indicador de la calidad de los datos, que era el precio. Unos datos caros siempre implicaban una alta calidad en su tratamiento, manipulación, limpieza y distribución.
Pero el aumento de la oferta y la tecnología, han democratizado en plan de precios de muchos proveedores, pudiendo conseguir de diferentes fuertes.
Por ejemplo, la única forma de gestionar un fondo de inversión en los 2000, era obligatoriamente mediante Bloomberg Terminal.
Los más arriesgados, utilizaban Reuters (Actualmente Eikon). Hoy en dia, su uso está más ligado a la integración de la tecnología con la compañía, que con la necesidad de datos de calidad.
Porque pese a que tienen una indiscutible calidad de datos, existen diferentes soluciones, por muchísimo menos del precio anual que una licencia de alguna de estas plataformas.
Además, para toda la gente, que está empezando en el trading cuantitativo, también pueden utilizar alguna de las datasources disponibles gratuitas.
Personalmente, antes de probar cualquier modelo con data real (de calidad), cuando estoy ajustando algo del modelo, o de el pipeline de ejecución, soy muy partidario de utilizar data de yahoo mediante la librería yfinance, básicamente porque en 2 líneas de código tengo los datos que necesito, una costumbre (mala) que debo empezar a corregir, dado que con el Datalake, se hace totalmente absurdo, ya que la plataforma que estamos creando sera muchísimo más rápida por definición.
Voy a nombrar ciertos proveedores, que, eliminando los sospechas habituales de bloomberg y eikon, cumplen en cierta forma con mis requisitos básicos para considerarlos como databrokers de calidad.
- Stocks : Nasdaq Data, Norgate Data, EODHD,IEX,
- Futuros : Norgate Data, Data Bentoo, Nasdaq Data, CME Data
- Bonos: GBONDs, FRED, EODHD
- Alternative: Nasdaq Data, EODHD,
- Crypto: EODHD, BINANCE, Coingecko
- Macro : JPM Synergic MACRO (Del cual hablaremos largo y tendido en futuras ocasiones)
Al final la decisión por elegir una fuente de datos, es tuya y solo tuya. Yo para desarrollar todo el datalake utilizando una premisa de que cualquiera pueda replicarlo en casa por un precio anecdótico, he utilizado EODHD y Databentoo y estoy satisfecho de los resultados en relación con el precio de la obtención de datos y la calidad de los datos obtenidos.
Proximamente
Una vez fijadas las características mínimas funcionales del proyecto y justificado la necesidad de su inclusión, en las próximas entregas vamos a crear un datalake desde 0. El objeto es crear una base estable y funcional como prueba de concepto de la tecnología.
El datalake estará programado en Python, utilizando la tecnología de Amazon AWS EC2 y los datos de EODHD y DataBentoo para futuros.
Generaremos una estructura básica de command and control, generaremos un proceso de ingest para volcar nuestra información en el datalake.
Utilizaremos diferentes fuentes de datos, como distintas apis, csvs, o datos recolectados por nosotros mismos (como puede ser un orderbook de alguna criptomoneda).
Con todo ello conseguiremos un datalake listo para empezar procesos de research sobre datos que probablemente no tenías acceso, o mejor dicho, nunca lo habías tenido todo centralizado en un mismo punto y con un formato amigable a las costumbres de la comunidad, como es el uso intensivo de pandas y sus pd.DataFrame().